|
I am a 3rd year Ph.D. student at UC San Diego, Dept. of Computer Science and Engineering. I am a part of the Biomedical Image Analysis Group, advised by Prof. Marc Niethammer. Currently, I am broadly working on multimodal learning and foundational models for 3D medical image analysis. My research interests broadly encompass multimodal learning (Vision + X), medical image segmentation and fine-grained representation learning. I transferred to UCSD from UNC Chapel Hill in Fall '25, where I was a CS PhD student previously. In Summer of '24, I was a research intern at SRI International, working with Anirban Roy on multimodal diffusion models for decoding fMRI to visual content. I also collaborate with Prof. Praneeth Chakravarthula of UNC Chapel Hill on unified image restoration and Prof. Josep Llados of CVC Barcelona on multimodal document understanding. I have also been fortunate enough to have collaborated with several research groups and academic institutions during my undergrad years: Prof. Umapada Pal and Prof. Saumik Bhattacharya at CVPR Unit, Indian Statistical Institute, Kolkata; Prof. Jose Dolz at ETS Montreal; Prof. Yi-Zhe Song at SketchX Lab, CVSSP, University of Surrey. I have published at top-tier computer vision / medical imaging / signal processing conferences, such as |

|

|
|
|
|
|
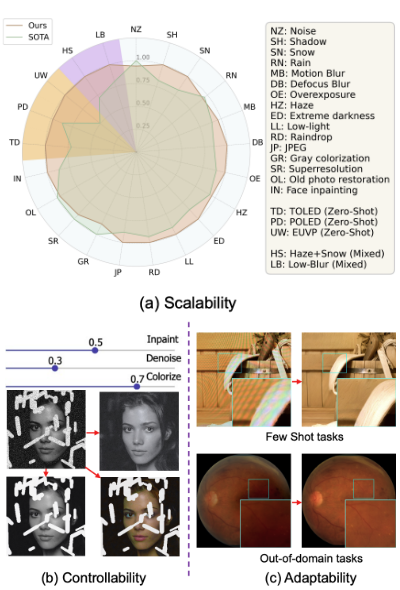
Debabrata Mandal, Soumitri Chattopadhyay, Yujie Wang, Marc Niethammer, Praneeth Chakravarthula Universal image restoration aims to recover clean images from arbitrary real-world degradations using a single inference model. Despite significant progress, existing all-in-one restoration networks do not scale to multiple degradations. As the number of degradations increases, training becomes unstable, models grow excessively large, and performance drops across both seen and unseen domains. In this work, we show that scaling universal restoration is fundamentally limited by interference across degradations during joint learning, leading to catastrophic task forgetting. To address this challenge, we introduce a unified inference pipeline with a multi-branch mixture-of-experts architecture that decomposes restoration knowledge across specialized task-adaptable experts. Our approach enables scalable learning (over sixteen degradations), adapts and generalizes robustly to unseen domains, and supports user-controllable restoration across degradations. Beyond achieving superior performance across benchmarks, this work establishes a new design paradigm for scalable and controllable universal image restoration. |
|
|
|
|
|
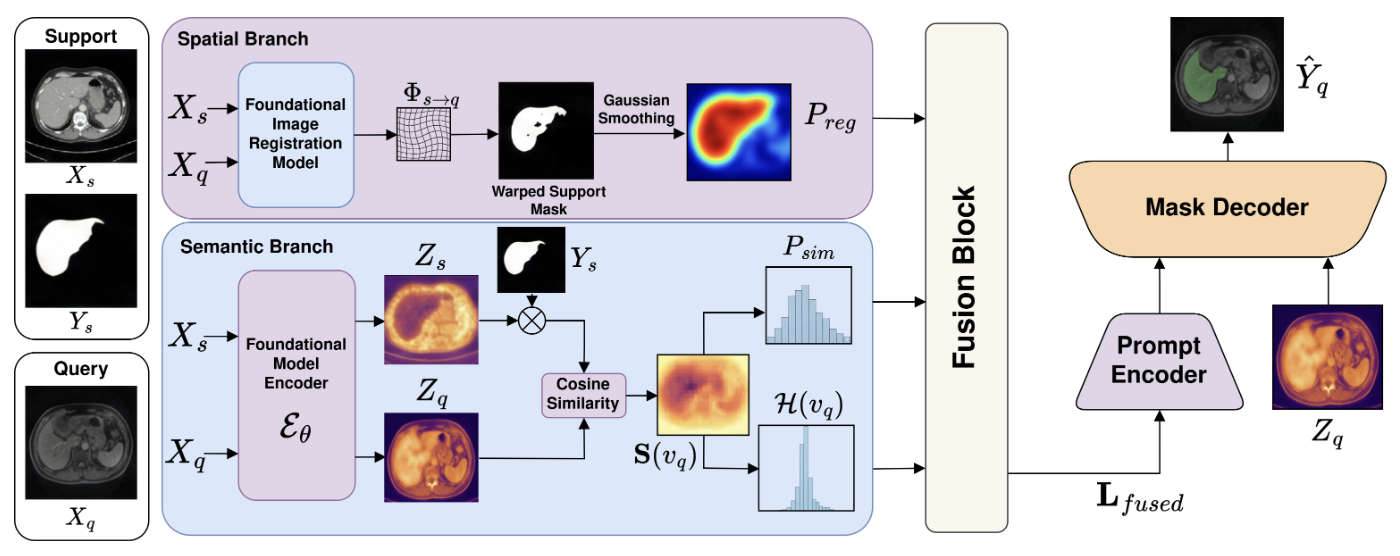
Soumitri Chattopadhyay, Basar Demir, Marc Niethammer The vast heterogeneity of medical imaging demands developing universal and modality-transferable segmentation models that can ideally work in low-data regimes. Although few-shot cross-domain, in-context learning, and promptable foundational models have emerged as promising data-efficient domain-agnostic solutions, they are all limited either in dimensionality (2D only), scalability (interactive prompting being too slow and iterative), or require re-training for each new task, limiting their general applicability. In this work, we address these limitations and propose a novel framework that harnesses the representational capabilities of foundational models to generate spatial and semantic contextual priors that holistically describe the target structure to be segmented. We also propose a confidence-weighted dynamic gating scheme to fuse these context maps into a single dense prompt, and re-purpose a frozen foundational segmentation model, SAM-Med3D, to predict segmentations using this fused representation instead of sparse points. Our framework is modality-agnostic, training-free, scalable, and enables rapid and robust universal segmentation. We validate our approach on two abdominal CT and MRI datasets under cross-modal and intra-modal settings, and show it outperforms existing state-of-the-art methods by significant margins. |
|
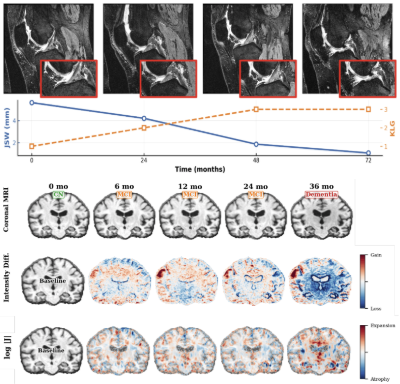
Basar Demir, Soumitri Chattopadhyay, Thomas Hastings Greer, Boqi Chen, Marc Niethammer Medical vision foundation models have shown strong performance across a range of tasks, including medical image segmentation and registration. In this work, we investigate their potential for disease progression prediction, a clinically important and challenging problem. We evaluate intermediate feature representations from pre-trained segmentation and registration models using a simple linear probe, without fine-tuning. We study two distinct clinical domains: knee osteoarthritis on the Osteoarthritis Initiative (OAI) dataset and Alzheimer's disease on the ADNI brain MRI dataset. We hypothesize that segmentation models, trained to delineate anatomical structures, primarily capture structural information, whereas registration models, trained to align images over time, inherently encode temporal change. Our results support this hypothesis across both domains. On OAI, registration features are robust to spatial misalignment and outperform segmentation features on unaligned inputs, while segmentation features require careful alignment to achieve competitive performance. On ADNI, registration features derived from baseline-to-follow-up alignment achieve the best results on longitudinal tasks, including long-horizon conversion prediction. Across both datasets, SAM-Med3D provides the strongest segmentation features, while registration features from baseline-to-current alignment best capture longitudinal disease progression. These findings hold across two anatomical regions and disease domains, highlighting the practical value of registration foundation model features for clinical progression prediction. |
|
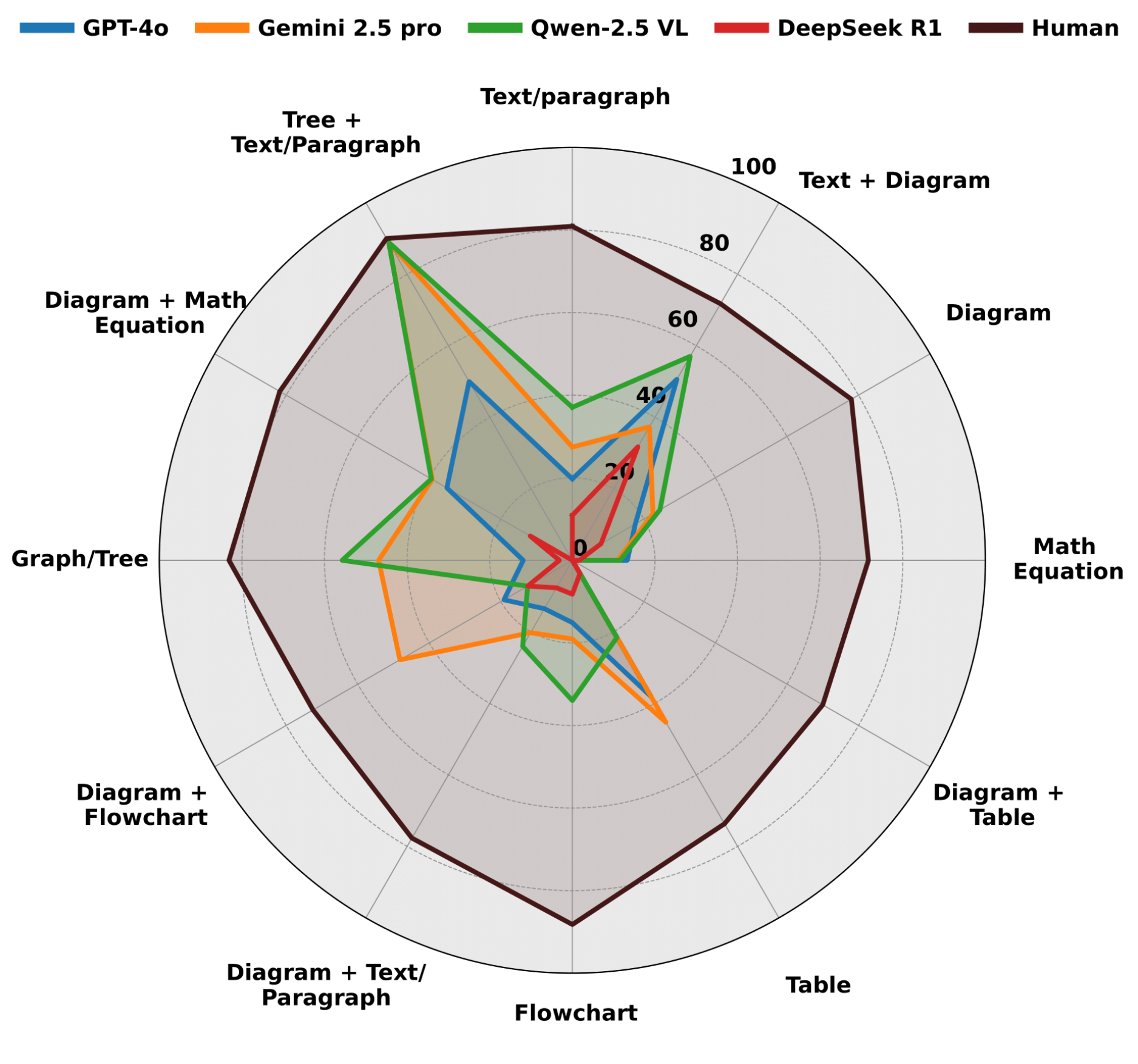
Alloy Das, Sanket Biswas, Soumitri Chattopadhyay, Ayush Lodh, Aniket Pal, Priyanka Banerjee, Nisha Singh, C.V. Jawahar, Josep Llados, Dimosthenis Karatzas Understanding and reasoning over academic handwritten notes remains a challenge in document AI, particularly for mathematical equations, diagrams, and scientific notations. Existing visual question answering (VQA) benchmarks fo- cus on printed or structured handwritten text, limiting gen- eralization to real-world note-taking. To address this, we introduce NOTES-BANK, an evaluation benchmark for Neural Transcription and Search in note-based question answering. NOTES-BANK comprises complex notes across multiple domains, requiring models to process unstructured and multimodal content. The benchmark defines two tasks: (1) Evidence-Based VQA, where models retrieve local- ized answers with bounding-box evidence, and (2) Open- Domain VQA, where models classify the domain before retrieving relevant documents and answers. Unlike clas- sical Document VQA datasets relying on optical charac- ter recognition (OCR) and structured data, NOTES-BANK demands vision-language fusion, retrieval, and multimodal reasoning. We benchmark state-of-the-art Vision-Language Models (VLMs) and retrieval frameworks, exposing struc- tured transcription and reasoning limitations. NOTES- BANK provides a rigorous evaluation with ANLS*, MRR, Recall@K, and IoU, establishing a new standard for visual document understanding and reasoning. |
|
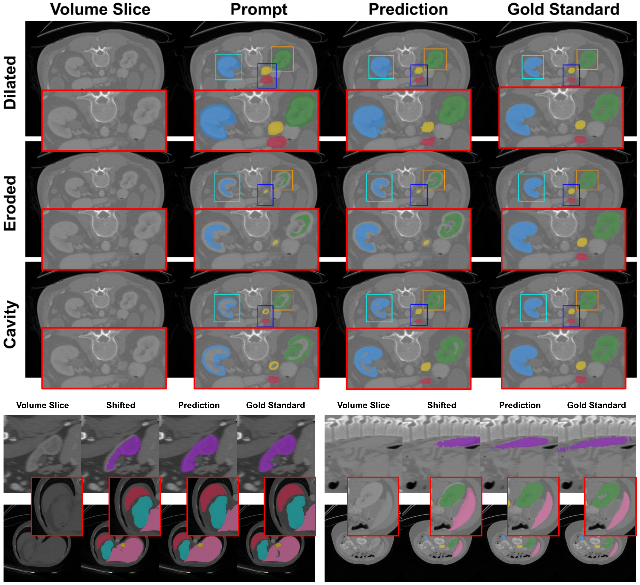
Soumitri Chattopadhyay, Basar Demir, Marc Niethammer arXiv / Code While 3D foundational models have shown promise for promptable segmentation of medical volumes, their robustness to imprecise prompts remains under-explored. In this work, we aim to address this gap by systematically studying the effect of various controlled perturbations of dense visual prompts, that closely mimic real-world imprecision. By conducting experiments with two recent foundational models on a multi-organ abdominal segmentation task, we reveal several facets of promptable medical segmentation, especially pertaining to reliance on visual shape and spatial cues, and the extent of resilience of models towards certain perturbations. |
|
|
|
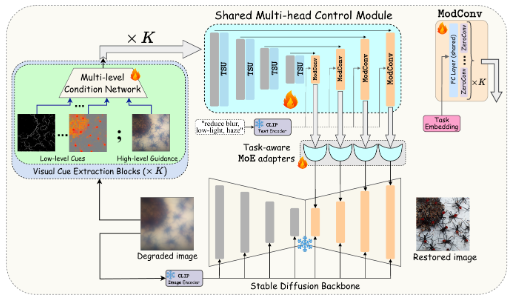
Debabrata Mandal, Soumitri Chattopadhyay, Guansen Tong, Praneeth Chakravarthula arXiv / Video / Dataset / Project Page Image restoration is essential for enhancing degraded images across computer vision tasks. However, most existing methods address only a single type of degradation (e.g., blur, noise, or haze) at a time, limiting their real-world applicability where multiple degradations often occur simultaneously. In this paper, we propose UniCoRN, a unified image restoration approach capable of handling multiple degradation types simultaneously using a multi-head diffusion model. Specifically, we uncover the potential of low-level visual cues extracted from images in guiding a controllable diffusion model for real-world image restoration and we design a multi-head control network adaptable via a mixture-of-experts strategy. We train our model without any prior assumption of specific degradations, through a smartly designed curriculum learning recipe. Additionally, we also introduce MetaRestore, a metalens imaging benchmark containing images with multiple degradations and artifacts. Extensive evaluations on several challenging datasets, including our benchmark, demonstrate that our method achieves significant performance gains and can robustly restore images with severe degradations. |
|
|
|
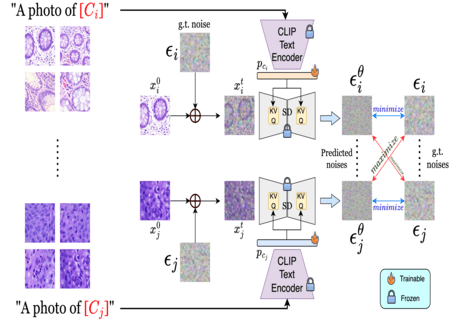
Soumitri Chattopadhyay, Sanket Biswas, Emanuele Vivoli, Josep Lladós arXiv / Code / Project Page Although foundational vision-language models (VLMs) have proven to be very successful for various semantic discrimination tasks, they still struggle to perform faithfully for fine-grained categorization. Moreover, foundational models trained on one domain do not generalize well on a different domain without fine-tuning. We attribute these to the limitations of the VLM's semantic representations and attempt to improve their fine-grained visual awareness using generative modeling. Specifically, we propose two novel methods: Generative Class Prompt Learning (GCPL) and Contrastive Multi-class Prompt Learning (CoMPLe). Utilizing text-to-image diffusion models, GCPL significantly improves the visio-linguistic synergy in class embeddings by conditioning on few-shot exemplars with learnable class prompts. CoMPLe builds on this foundation by introducing a contrastive learning component that encourages inter-class separation during the generative optimization process. Our empirical results demonstrate that such a generative class prompt learning approach substantially outperform existing methods, offering a better alternative to few shot image recognition challenges. |
|
|
|
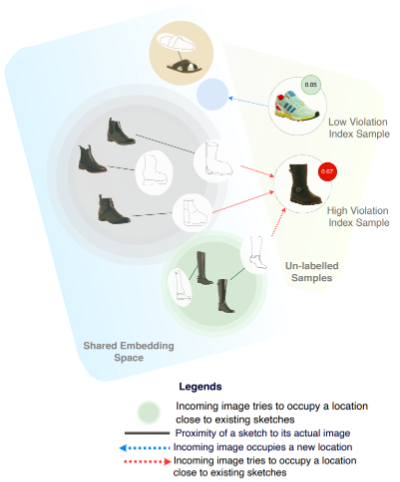
Himanshu Thakur*, Soumitri Chattopadhyay* arXiv / Poster / Video The ability to retrieve a photo by mere free-hand sketching highlights the immense potential of Fine-grained sketch-based image retrieval (FG-SBIR). However, its rapid practical adoption, as well as scalability, is limited by the expense of acquiring faithful sketches for easily available photo counterparts. A solution to this problem is Active Learning, which could minimise the need for labeled sketches while maximising performance. Despite extensive studies in the field, there exists no work that utilises it for reducing sketching effort in FG-SBIR tasks. To this end, we propose a novel active learning sampling technique that drastically minimises the need for drawing photo sketches. Our proposed approach tackles the trade-off between uncertainty and diversity by utilising the relationship between the existing photo-sketch pair to a photo that does not have its sketch and augmenting this relation with its intermediate representations. Since our approach relies only on the underlying data distribution, it is agnostic of the modelling approach and hence is applicable to other cross-modal instance-level retrieval tasks as well. With experimentation over two publicly available fine-grained SBIR datasets ChairV2 and ShoeV2, we validate our approach and reveal its superiority over adapted baselines. |
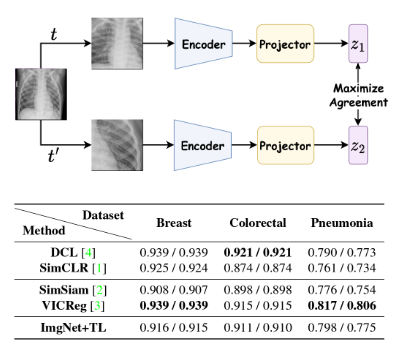
|
Soumitri Chattopadhyay, Soham Ganguly*, Sreejit Chaudhury*, Sayan Nag*, Samiran Chattopadhyay arXiv / Code / Video The success of self-supervised learning (SSL) has mostly been attributed to the availability of unlabeled yet large-scale datasets. However, in a specialized domain such as medical imaging which is a lot different from natural images, the assumption of data availability is unrealistic and impractical, as the data itself is scanty and found in small databases, collected for specific prognosis tasks. To this end, we seek to investigate the applicability of self-supervised learning algorithms on small-scale medical imaging datasets. In particular, we evaluate 4 state-of-the-art SSL methods on three publicly accessible small medical imaging datasets. Our investigation reveals that in-domain low-resource SSL pre-training can yield competitive performance to transfer learning from large-scale datasets (such as ImageNet). Furthermore, we extensively analyse our empirical findings to provide valuable insights that can motivate for further research towards circumventing the need for pre-training on a large image corpus. To the best of our knowledge, this is the first attempt to holistically explore self-supervision on low-resource medical datasets. |
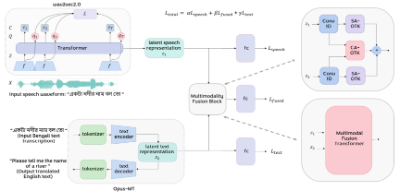
|
Ahana Deb*, Sayan Nag*, Ayan Mahapatra*, Soumitri Chattopadhyay*, Aritra Marik*, Pijush Kanti Gayen, Shankha Sanyal, Archi Banerjee, Samir Karmakar arXiv / Project Page Spoken languages often utilise intonation, rhythm, intensity, and structure, to communicate intention, which can be interpreted differently depending on the rhythm of speech of their utterance. These speech acts provide the foundation of communication and are unique in expression to the language. Recent advancements in attention-based models, demonstrating their ability to learn powerful representations from multilingual datasets, have performed well in speech tasks and are ideal to model specific tasks in low resource languages. Here, we develop a novel multimodal approach combining two models, wav2vec2.0 for audio and MarianMT for text translation, by using multimodal attention fusion to predict speech acts in our prepared Bengali speech corpus. We also show that our model BeAts (Bengali speech acts recognition using Multimodal Attention Fusion) significantly outperforms both the unimodal baseline using only speech data and a simpler bimodal fusion using both speech and text data. |
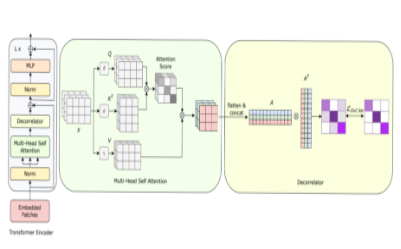
|
Mayukh Bhattacharyya*, Soumitri Chattopadhyay*, Sayan Nag* Paper / Code / Slides The advent of Vision Transformers (ViT) has led to significant performance gains across various computer vision tasks over the last few years, surpassing the de facto standard CNN architectures. However, most of the prominent variations of Vision Transformers are resource-intensive architectures with huge parameter sizes. They are known to be data-hungry and overfit quickly on comparatively smaller datasets. Consequently, this holds back their widespread usage across low-resource settings, which brings forth the need to develop resource-efficient vision transformers. To this end, we introduce a regularization loss that prioritizes efficient utilization of model parameters by decorrelating the heads of a multi-headed attention block in a vision transformer. This forces the heads to learn distinct features rather than focus on the same ones. Using this loss provides a consistent performance improvement over a wide range of varying scenarios of models and datasets as we show in our experiments, which proves its superior effectiveness. |
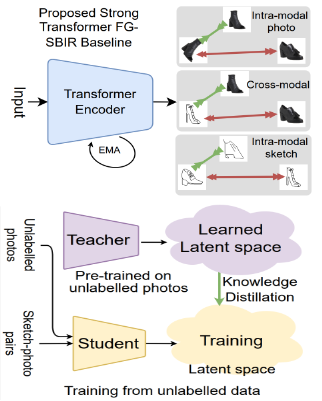
|
Aneeshan Sain, A. K. Bhunia, Subhadeep Koley, P. N. Chowdhury, Soumitri Chattopadhyay, Tao Xiang, Yi-Zhe Song arXiv / Project Page / Video This paper advances the fine-grained sketch-based image retrieval (FG-SBIR) literature by putting forward a strong baseline that overshoots prior state-of-the art by ~11%. This is not via complicated design though, but by addressing two critical issues facing the community (i) the gold standard triplet loss does not enforce holistic latent space geometry, and (ii) there are never enough sketches to train a high accuracy model. For the former, we propose a simple modification to the standard triplet loss, that explicitly enforces separation amongst photos/sketch instances. For the latter, we put forward a novel knowledge distillation module can leverage photo data for model training. Both modules are then plugged into a novel plug-n-playable training paradigm that allows for more stable training. More specifically, for (i) we employ an intra-modal triplet loss amongst sketches to bring sketches of the same instance closer from others, and one more amongst photos to push away different photo instances while bringing closer a structurally augmented version of the same photo (offering a gain of 4-6%). To tackle (ii), we first pre-train a teacher on the large set of unlabelled photos over the aforementioned intra-modal photo triplet loss. Then we distill the contextual similarity present amongst the instances in the teacher's embedding space to that in the student's embedding space, by matching the distribution over inter-feature distances of respective samples in both embedding spaces (delivering a further gain of 4-5%). Apart from outperforming prior arts significantly, our model also yields satisfactory results on generalising to new classes. |
|
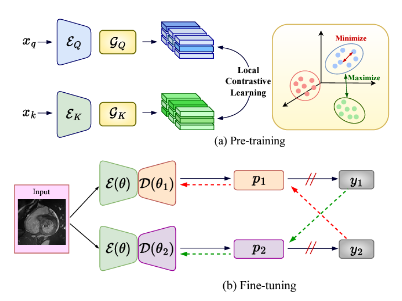
Hritam Basak, Soumitri Chattopadhyay*, Rohit Kundu*, Sayan Nag*, Rammohan Mallipeddi arXiv / Code / Project Page Due to the scarcity of labeled data, Contrastive Self-Supervised Learning (SSL) frameworks have lately shown great potential in several medical image analysis tasks. However, the existing contrastive mechanisms are sub-optimal for dense pixel-level segmentation tasks due to their inability to mine local features. To this end, we extend the concept of metric learning to the segmentation task, using a dense (dis)similarity learning for pre-training a deep encoder network, and employing a semi-supervised paradigm to fine-tune for the downstream task. Specifically, we propose a simple convolutional projection head for obtaining dense pixel-level features, and a new contrastive loss to utilize these dense projections thereby improving the local representations. A bidirectional consistency regularization mechanism involving two-stream model training is devised for the downstream task. Upon comparison, our IDEAL method outperforms the SoTA methods by fair margins on cardiac MRI segmentation. |
|
|
|
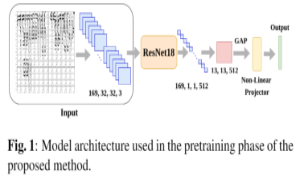
Siladittya Manna, Soumitri Chattopadhyay, Saumik Bhattacharya, Umapada Pal arXiv / Code / Slides Writer independent offline signature verification is one of the most challenging tasks in pattern recognition as there is often a scarcity of training data. To handle such data scarcity problem, in this paper, we propose a novel self-supervised learning (SSL) framework for writer independent offline signature verification. To our knowledge, this is the first attempt to utilize self-supervised setting for the signature verification task. The objective of self-supervised representation learning from the signature images is achieved by minimizing the cross-covariance between two random variables belonging to different feature directions and ensuring a positive cross-covariance between the random variables denoting the same feature direction. This ensures that the features are decorrelated linearly and the redundant information is discarded. Through experimental results on different data sets, we obtained encouraging results. |
|
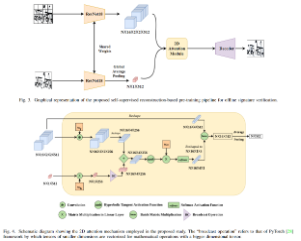
Soumitri Chattopadhyay, Siladittya Manna, Saumik Bhattacharya, Umapada Pal arXiv / Code / Video Offline Signature Verification (OSV) is a fundamental biometric task across various forensic, commercial and legal applications. The underlying task at hand is to carefully model fine-grained features of the signatures to distinguish between genuine and forged ones, which differ only in minute deformities. This makes OSV more challenging compared to other verification problems. In this work, we propose a two-stage deep learning framework that leverages self-supervised representation learning as well as metric learning for writer-independent OSV. First, we train an image reconstruction network using an encoder-decoder architecture that is augmented by a 2D spatial attention mechanism using signature image patches. Next, the trained encoder backbone is fine-tuned with a projector head using a supervised metric learning framework, whose objective is to optimize a novel dual triplet loss by sampling negative samples from both within the same writer class as well as from other writers. The intuition behind this is to ensure that a signature sample lies closer to its positive counterpart compared to negative samples from both intra-writer and cross-writer sets. This results in robust discriminative learning of the embedding space. To the best of our knowledge, this is the first work of using self-supervised learning frameworks for OSV. The proposed two-stage framework has been evaluated on two publicly available offline signature datasets and compared with various state-of-the-art methods. It is noted that the proposed method provided promising results outperforming several existing pieces of work. |
- MICCAI 2026, MICCAI 2025, ISBI 2026 - CVPR Workshops: ECV @ CVPR'23,'24; T4V @ CVPR'24 - ICCV Workshops: WiCV @ ICCV'23 - ICPR 2022, 2024 - Cluster Computing ('24-Present) - Engineering Applications of Artificial Intelligene, Elsevier ('23-Present) - Computers in Biology and Medicine, Elsevier ('21-Present) - International Journal of Intelligent Systems, Wiley ('22-Present) - Informatics in Medicine Unlocked, Elsevier ('22-Present) |
| © Soumitri Chattopadhyay | Last updated: June 2026 | Thanks to Jon Barron for sharing this awesome template! |